Run Meta Llama 3.2 1B & 3B Models Locally on iOS Devices
Update: Uncensored Llama 3.2 finetunes are here for Private LLM on iOS and macOS! Plus, we've added Llama 3.3 70B for Mac users. If you have an Apple Silicon Mac with more than 48GB of RAM, you can now run this advanced model entirely on your device.
We're excited to announce the release of Private LLM for iOS v1.8.9, now featuring support for Meta's Llama 3.2 models. This update brings advanced AI capabilities to your iPhone and iPad, allowing you to run Llama 3.2 locally on your device.
Meta's Llama 3.2 is a collection of multilingual large language models (LLMs) available in 1B and 3B parameter sizes. These models are optimized for multilingual dialogue, including agentic retrieval and summarization tasks. Llama 3.2 uses an optimized transformer architecture and has been trained on up to 9 trillion tokens of data from publicly available sources, with a knowledge cutoff of December 2023.
One more thing. Although people in the on-device LLM space often avoid talking about this aspect, we think we ought to be honest here. Quantization is a compromise, and we hate compromises. We use OmniQuant quantization for models because it’s one of the best compromises that can make when it comes to quantization. But it’s a compromise nonetheless. We look forward to the day when hardware is good enough for people can run unquantized models on their phones. If you have a iPhone Pro/Pro Max phone (iPhone 12 Pro or newer), then that day is today. You can run Llama 3.2 1B Instruct unquantized on your iPhone, today!
For anyone interested in knowing more about how quantization affects LLM performance, we recommend the excellent Physics of Language models paper and lecture series.
Llama 3.2 Key Features:
-
Multilingual Support: Officially supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, with potential for fine-tuning in additional languages.
-
Advanced Architecture: Utilizes Grouped-Query Attention (GQA) for improved inference scalability.
-
Extensive Training: Incorporates knowledge distillation techniques and multiple rounds of alignment, including Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
Run Llama 3.2 Locally on Your iOS Device
Private LLM now harnesses the capabilities of Llama 3.2, bringing cutting-edge AI directly to your iPhone or iPad:
-
Uncompromising Privacy: With all processing occurring locally, your data never leaves your device, ensuring complete confidentiality.
-
Superior Performance: OmniQuant quantization technique outperforms alternatives, delivering faster and more efficient text generation compared to Ollama and other llama.cpp wrappers using RTN quantization.
-
True Offline Functionality: Access powerful AI capabilities anytime, anywhere, without the need for an internet connection.
-
The Llama 3.2 1B model runs smoothly on any iOS device, while the Llama 3.2 3B model operates efficiently on devices with at least 6GB of RAM. Similarly, the high-quality unquantized fp16 version of Llama 3.2 1B model runs on any iOS device with at least 6GB of RAM (All Pro and Pro Max phones from iPhone 12 Pro onwards and all iPhone 15 and 16 series iPhones, and also Apple Silicon iPads with M1/M2/M4 chips).
-
The maximum context length is currently set to 8k tokens for all three models due to on-device memory constraints. Note that the base models support up to 128k tokens in context length, but the KV cache for the full context length would be 4GB with the 1B model and around 15GB for the 3B model. We might selectively increase the context length as appropriate in future releases for iOS devices with more memory like iPhone 15 Pro and Pro Max, the iPhone 16 series and the M-series iPads.
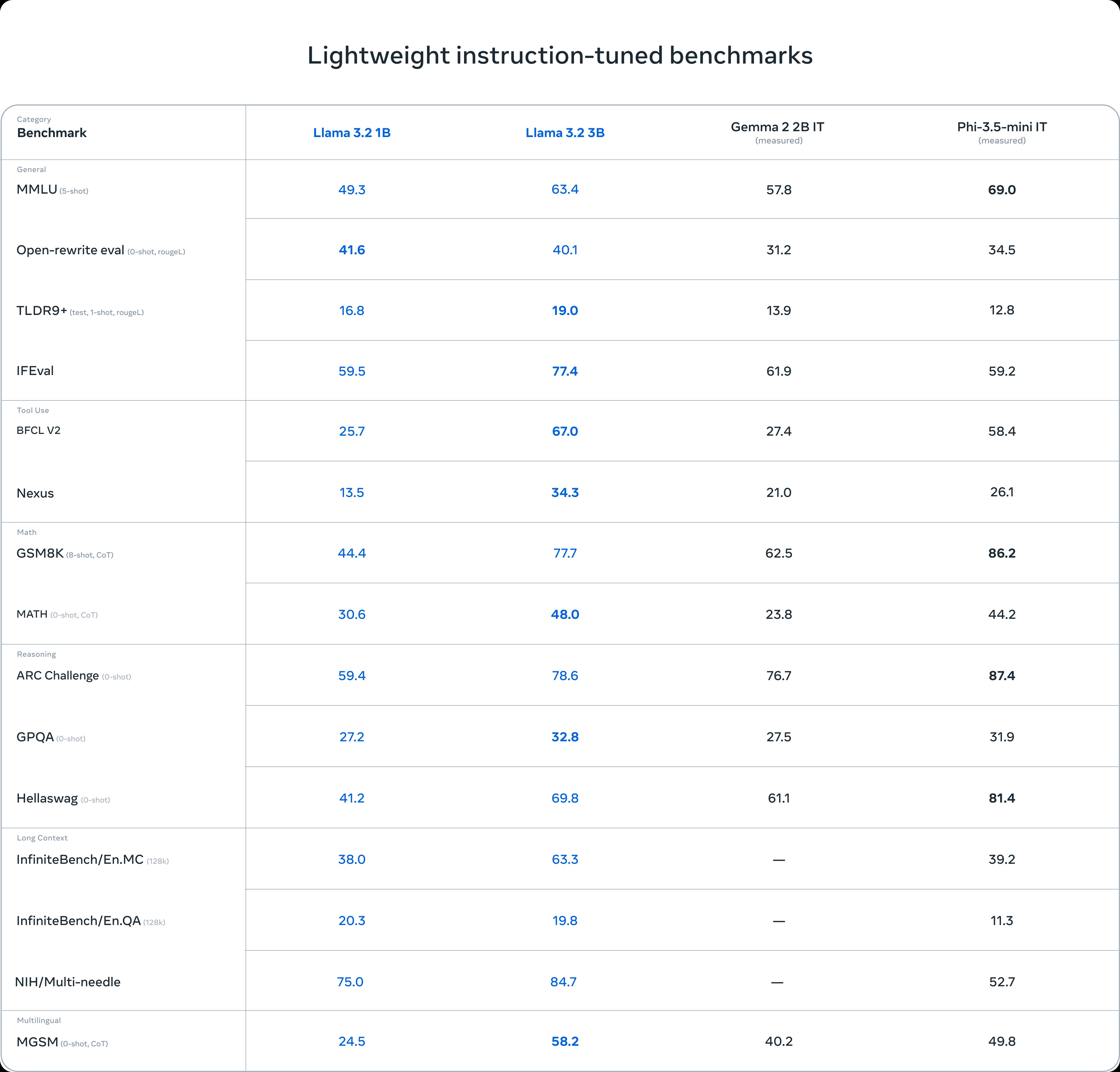
Llama 3.2 Benchmarks: Leading the Pack
Benchmarks showcase Llama 3.2's impressive capabilities, particularly when compared to other models in its class:
Instruction Tuned Models (3B version):
- MMLU (general knowledge): Llama 3.2 3B scores 63.4, outperforming Gemma 2 2B IT (57.8) and approaching Phi-3.5-mini IT (69.0)
- ARC Challenge (reasoning): Llama 3.2 3B achieves 78.6, surpassing Gemma 2 2B IT (76.7) and closing in on Phi-3.5-mini IT (87.4)
- GSM8K (math, Chain-of-Thought): Llama 3.2 3B excels with 77.7, significantly outperforming Gemma 2 2B IT (62.5) and nearing Phi-3.5-mini IT (86.2)
The Llama 3.2 1B model also demonstrates competitive performance, making it an excellent choice for devices with limited resources.
Multilingual Proficiency of Llama 3.2
Llama 3.2 demonstrates strong multilingual capabilities. For example, on the 5-shot MMLU benchmark:
- Portuguese: 54.48
- Spanish: 55.1
- Italian: 53.8
- German: 53.3
- French: 54.6
- Hindi: 43.3
- Thai: 44.5
These scores for the 3B model showcase its ability to handle diverse languages effectively.
Download Llama 3.2 on Your iPhone or iPad
To enjoy Llama 3.2 fully offline on your iOS device, download or update Private LLM from the App Store. Once installed, you can download the Llama 3.2 model directly within the app. This seamless process allows you to quickly start exploring the capabilities of local, privacy-focused AI on your iPhone or iPad.
By bringing Llama 3.2 to Private LLM, we're providing users with access to state-of-the-art AI technology that respects privacy and operates efficiently on local devices. Whether you're a developer, researcher, or enthusiast, this update opens new possibilities for on-device AI applications.