Local LLM on iPhone, iPad, and Mac: Run Local AI Offline
Every message you send to a cloud chatbot leaves your phone. Every conversation from a local LLM on iPhone, iPad, or Mac never does. Download a model once, and everything after that runs offline: no internet, no account, no API key, no subscription. Private LLM is the Apple-native app built for exactly this. Install it, pick a model sized to your hardware, and start chatting entirely on-device. This guide covers the best local LLM apps for iPhone and iPad in 2026, which Mac runs Llama 3.3 70B, system prompts, sampling, Siri and Shortcuts integration, and what Private LLM does differently from Ollama and LM Studio.
Key Takeaways
- Private LLM runs 140+ open-source models on iPhone, iPad, and Mac entirely on-device, with no internet connection required after model download.
- Match the model to the hardware: iPhone 15 Pro runs Llama 3.1 8B, a 48GB Apple Silicon Mac runs Llama 3.3 70B, older 4GB iPhones run Llama 3.2 1B and Qwen3 4B.
- OmniQuant and GPTQ quantization produce measurably better text quality than the RTN quantization used by Ollama and LM Studio on the same hardware.
- One purchase covers all your Apple devices plus Family Sharing for six people. No subscription, no usage cap, no logging.
- Siri and Apple Shortcuts integration turns the app into a local GPT-style assistant callable from any iOS or macOS surface.
Here's what sets Private LLM apart from other AI chatbots:
-
Offline Processing: Your data stays on your device, with local processing that ensures complete privacy and security.
-
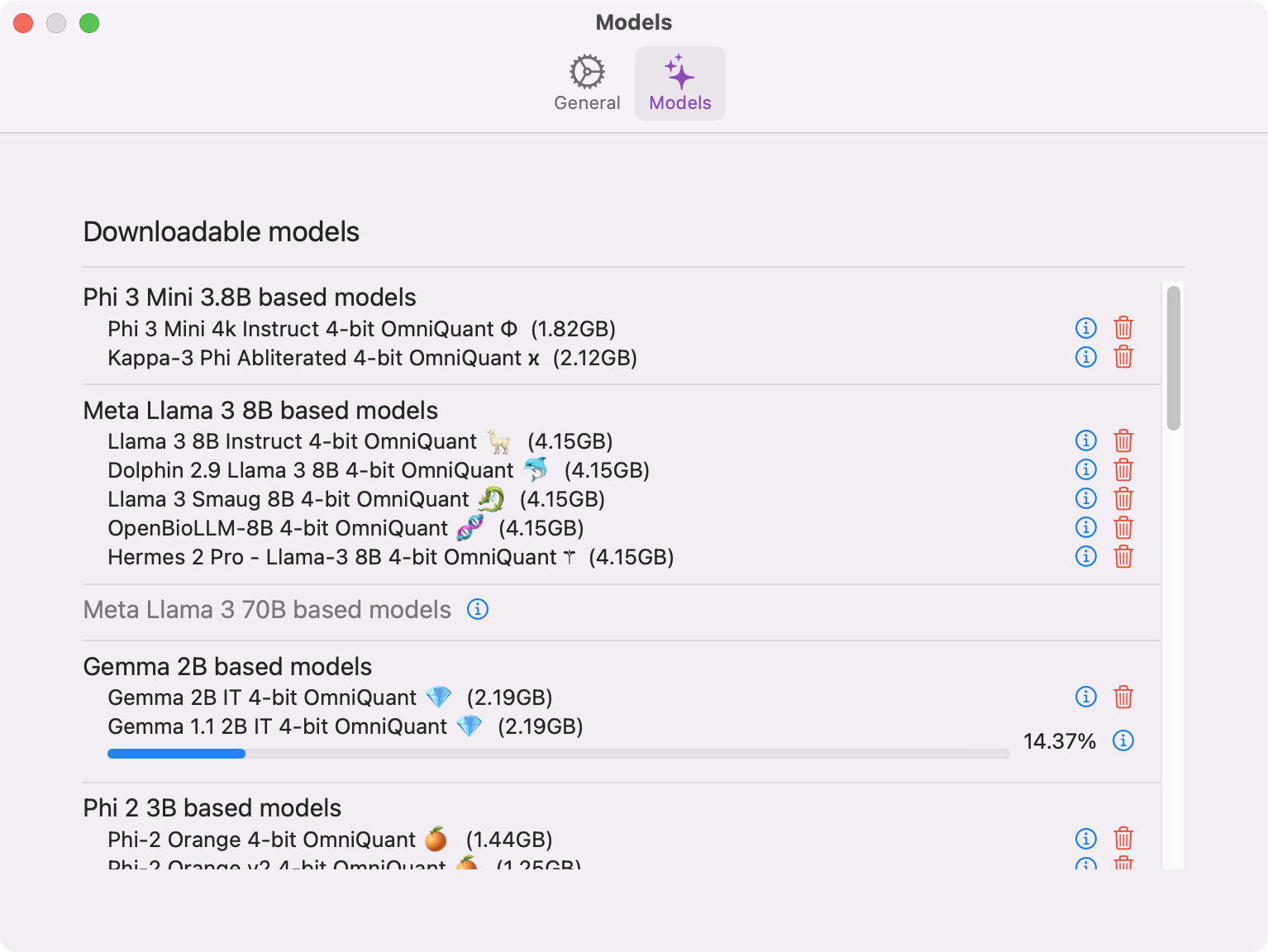
Extensive Model Support: Access 140+ open-source models including DeepSeek R1 Distill, Llama 3.3 70B, Llama 3.2, Qwen3 4B, Qwen 2.5, Phi 4, and Google Gemma 3. Each model offers unique capabilities optimized for different tasks and devices.
-
Apple Ecosystem Integration: Create AI workflows using Siri, Apple Shortcuts, and system-wide macOS services.
-
One-Time Purchase: Buy once, use forever on all your Apple devices with Family Sharing for up to six users. Download new models at no extra cost, with App Store refund support if needed.
-
Advanced Model Performance: Leverage both OmniQuant and GPTQ quantization for superior performance. Our 3-bit OmniQuant models match or exceed 4-bit alternatives, while custom optimization ensures faster inference and better text generation compared to pre-made GGUF files. Learn more in our Ollama vs Private LLM comparison.
-
Uncensored AI Models: Run advanced unrestricted and roleplay specialized models locally, featuring top performers from the UGI Leaderboard like EVA Llama and Tiger Gemma series. Whether you're exploring creative writing, character roleplay, or open dialogue, customize your experience using proven system prompts from the Dolphin messages repository.
How do I run a local LLM on iPhone?
Install Private LLM from the App Store, open the Models screen, and download one sized to your device: Llama 3.2 3B or Qwen3 4B on most iPhones, Llama 3.1 8B on iPhone 15 Pro and iPhone 16 Pro. Once the weights land on the device, every chat runs fully offline. No API key, no account, no internet required for inference. The same flow works on iPad and Mac, with bigger models available as your unified memory grows.
That's it. Private LLM turns your iPhone, iPad, or Mac into an offline AI assistant the moment the download finishes. Chat with DeepSeek R1 Distill, Phi 4, Qwen3, or Llama 3.3 directly on the device, no internet, no API key required. Whether you're on a new M4 Mac or an older iPhone, start with Private LLM on the App Store.
Understanding System Prompts
A system prompt is the instruction that steers everything that follows it. Set it once, and the model holds that role for the whole conversation, whether that's a coding partner or a patient tutor.

For example, if you wanted to use Private LLM as a creative writing assistant, you could provide a system prompt like: "You are an imaginative story writer. Expand on the user's writing prompts to create vivid, detailed scenes that draw the reader in. Focus on sensory details, character development, and plot progression."
Or if you needed help studying for a history exam, your prompt might be: "Act as an expert history tutor. When the user asks about a historical event or period, provide a concise summary of the key facts, dates, and figures. Then ask follow-up questions to test their understanding and help reinforce the material."
Note: Google Gemma and Gemma 2 based models do not support system prompts. Gemma 3 does.
Popular System Prompt Use Cases
- Coding assistant: Guide the AI to help with programming tasks, debugging, and code explanations
- Writing companion: Set the AI to assist with content creation, editing, and style improvements
- Research helper: Configure the AI for document analysis, data interpretation, and literature reviews
- Language tutor: Create prompts for language learning, translation, and grammar correction
- Creative collaborator: Enable brainstorming sessions, story development, and artistic ideation
For advanced users interested in uncensored conversations, check out the comprehensive collection of Dolphin system messages on GitHub. These community-curated prompts showcase the full range of possibilities with unrestricted models.
Start with basic prompts and gradually refine them based on your needs. The key is experimentation – try different approaches to discover what works best for your specific use cases.
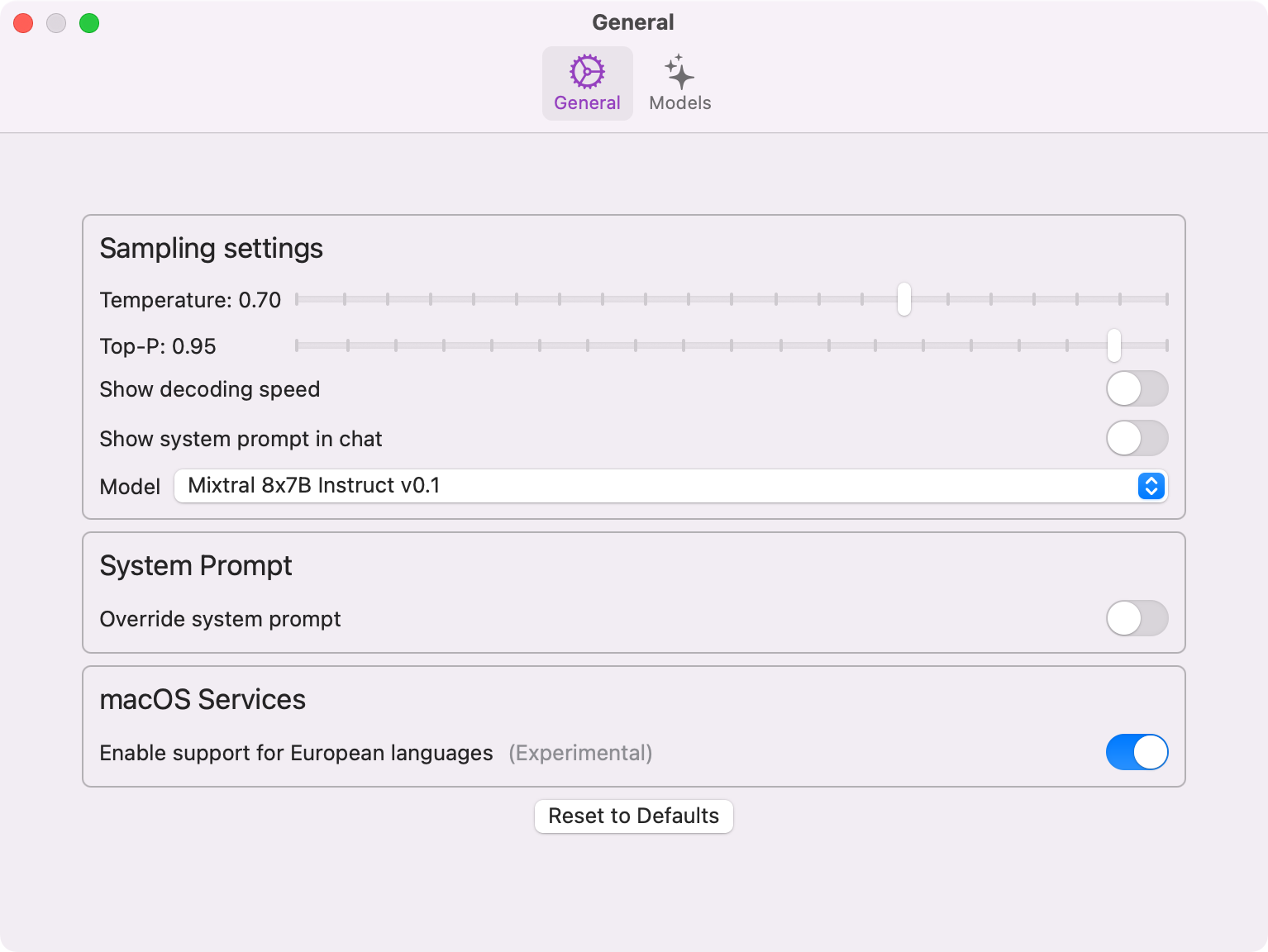
Understanding Sampling Settings
Private LLM hands you direct control over how the model generates text, through two settings: Temperature and Top-P.
Temperature
Temperature is a value that ranges from 0 to 1 and controls the randomness of the model's output. A lower temperature (closer to 0) makes the output more focused and deterministic, which is ideal for analytical tasks or answering multiple-choice questions. A higher temperature (closer to 1) introduces more randomness, making the output more diverse and creative. This is better suited for open-ended, generative tasks like story writing or brainstorming.
For example, if you're using Private LLM to generate a poem, you might set the temperature to around 0.8 to encourage the model to come up with novel and imaginative lines. On the other hand, if you're asking the AI to solve a math problem, a temperature of 0.2 would ensure it stays focused on finding the correct answer.
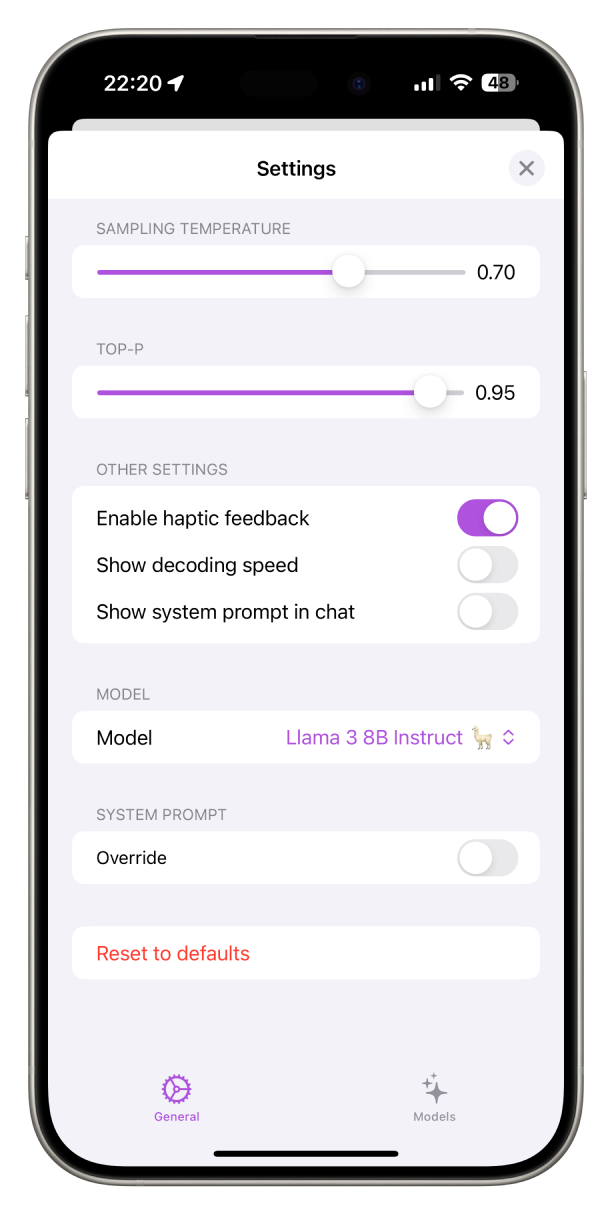
Top-P
Top-P, also known as nucleus sampling, is another way to control the model's output. It works by selecting the next token (word or subword) from the most probable options until the sum of their probabilities reaches the specified Top-P value. A Top-P of 1 means the model will consider all possible tokens, while a lower value like 0.5 will only consider the most likely ones that together make up 50% of the probability mass.
Top-P can be used in combination with temperature to fine-tune the model's behavior. For instance, if you're generating a news article, you might set the temperature to 0.6 and Top-P to 0.9. This would ensure the output is coherent and relevant (by limiting the randomness with temperature) while still allowing for some variation in word choice (by considering a larger pool of probable tokens with Top-P).
To help you get started, here are some recommended sampling settings for different use cases:
Creative/Chat mode works well for casual conversations, storytelling, and brainstorming:
- Temperature: 0.7
- Top-p: 0.9
Focused/Precise mode is ideal for analysis, coding, and fact-based responses:
- Temperature: 0.3
- Top-p: 0.7
Deterministic mode ensures consistent, reproducible outputs:
- Temperature: 0.0
- Top-p: 1.0
Feel free to experiment with these values and adjust them based on your needs. The optimal settings may vary depending on the model you're using and your specific task.
Best Local LLM Apps for iPhone and iPad in 2026
When picking a local LLM for iPhone or iPad, the constraint is RAM, not the App Store. Match the model to the device and every tier runs well. Here's what we recommend by RAM class:
- iPhone 15 Pro and iPhone 16 Pro (8GB RAM): Meta Llama 3.1 8B and Qwen 2.5 7B based models.
- M-series iPad Pro with 16GB RAM (1TB+ SSD): Google Gemma 3 9B or Qwen 2.5 14B based models (exclusive to this configuration due to 16GB RAM).
- M1/M2 iPads with 8GB RAM: Meta Llama 3.1 8B and Qwen 2.5 7B based models.
- Older iPhones with 6GB RAM (iPhone 12 Pro, 13 Pro, 14 Pro): Meta Llama 3.2 3B and Qwen3 4B based models.
- Other iPhones with 4GB RAM: Meta Llama 3.2 1B, Qwen 2.5 0.5B/1.5B/3B, and Google Gemma 3 1B based models.
- For uncensored chats: We support many highly ranked models from the UGI Leaderboard. Current suggestions include Tiger Gemma 9B v3, Llama 3.2 Abliterated, and Llama 3.1 8B Lexi Uncensored V2 (device requirements match the above models).
- For role play chats: EVA Qwen2.5 14B v0.2, EVA Qwen2.5 7B v0.1, EVA-D Qwen2.5 1.5B v0.0.
Best Local LLM Apps for Mac in 2026
On Mac the constraint is unified memory, not the app. The bigger your Apple Silicon, the bigger the local LLM you can run:
- Macs with at least 48GB RAM: Meta Llama 3.3 70B and Qwen 2.5 32B based models; DeepSeek R1 Distill 70B variants.
- Macs with at least 24GB RAM: Microsoft Phi 4, Qwen 2.5 32B, Qwen 2.5 14B, and Google Gemma 3 9B based models.
- Macs with at least 8GB RAM: Google Gemma 3 9B based models, Meta Llama 3.1 8B, and Qwen 2.5 7B based models.
Choose a model based on your Mac's specifications and desired use cases for optimal performance. Check out the full list of models for more options.
Understanding Context Length
Context length is how much text a model can hold in a single input. Feed it a long document past that limit and it starts dropping the parts that matter, so match the model to how much text you actually need it to read at once.
iPhone or iPad
For iOS devices, if you plan to process extensive text, consider models with larger context windows. Meta Llama 3.1 8B Instruct and Qwen 2.5 7B support 8K context, enabling analysis of longer documents and extended conversations. For coding tasks, Qwen 2.5 Coder offers specialized capabilities with the same context length. Mid-range devices can use Llama 3.2 3B or Google Gemma 3, while older devices work well with Llama 3.2 1B or Qwen 2.5 1.5B, which provide 4K context.
Mac
On Mac, memory capacity determines available context lengths. For systems with 48GB+ RAM, Llama 3.3 70B Instruct offers a 32K context window, ideal for processing extensive documents and complex analyses. Macs with 32GB RAM can utilize Microsoft Phi 4, Qwen 2.5 32B or Qwen 2.5 Coder 32B for similar capabilities. For systems with less RAM, we recommend following our high-end iPhone model suggestions or checking our model list for detailed memory requirements and context lengths.
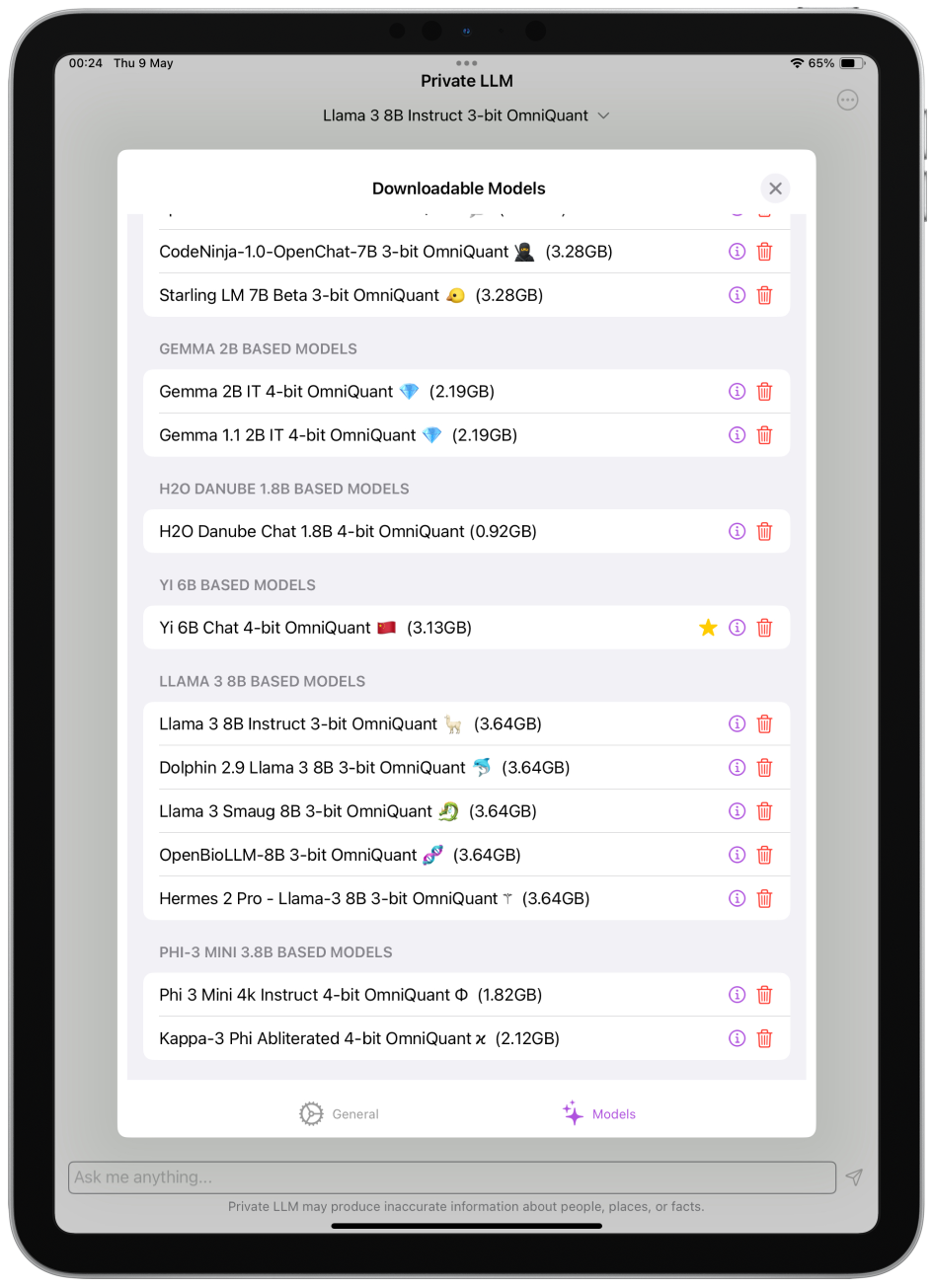
Downloading New AI Models
Downloading a new model in Private LLM takes one trip to the app's settings and a tap on the model you want. Sizes vary, from a few hundred megabytes to several gigabytes, depending on the model.
Due to iOS limitations, you must keep the app open during the download process on your iPhone or iPad, as background downloads are not supported. Additionally, users can only download one model at a time on iOS devices. These limitations do not apply to Mac.
Be patient, as larger models may take some time to download fully. Remember, with Private LLM's one-time purchase, you can download new models for free forever, with no subscription required.
Integrating with iOS and macOS Features and Custom Workflows
Private LLM's integration with Apple Shortcuts is one of its most powerful features, because it turns a chat app into a building block. Combine Private LLM with Shortcuts and you can automate repetitive tasks or chain them into a workflow that fits your day.
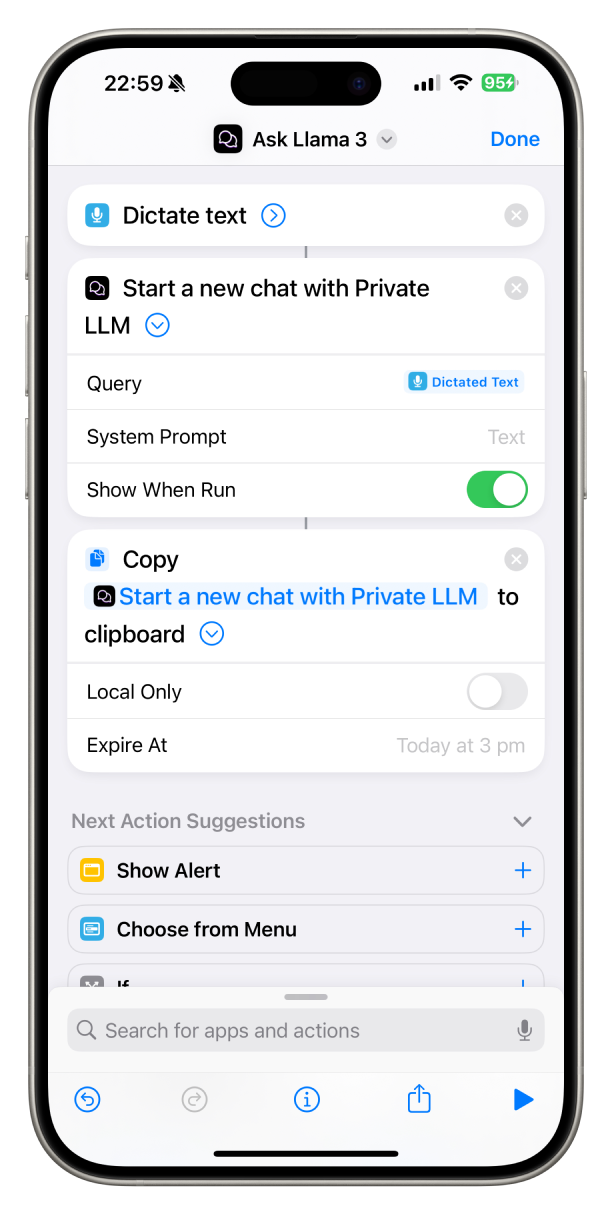
By crafting specific prompts and integrating them with Apple Shortcuts, users can guide the AI model to produce desired outputs. This technique, known as prompt engineering, enables the creation of powerful workflows tailored to individual needs. For example, the "Ask Llama 3" shortcut demonstrates a simple way to interact with a private on-device AI. Users can dictate their query in English, which is processed by the "Dictate Text" action and sent to Private LLM via the "Start a new chat with Private LLM" action. The AI's response can be displayed instantly or copied to the clipboard for later use. This user-friendly shortcut showcases the seamless integration of voice commands and AI chatbot functionality, making it an excellent introduction to the potential of combining these technologies.
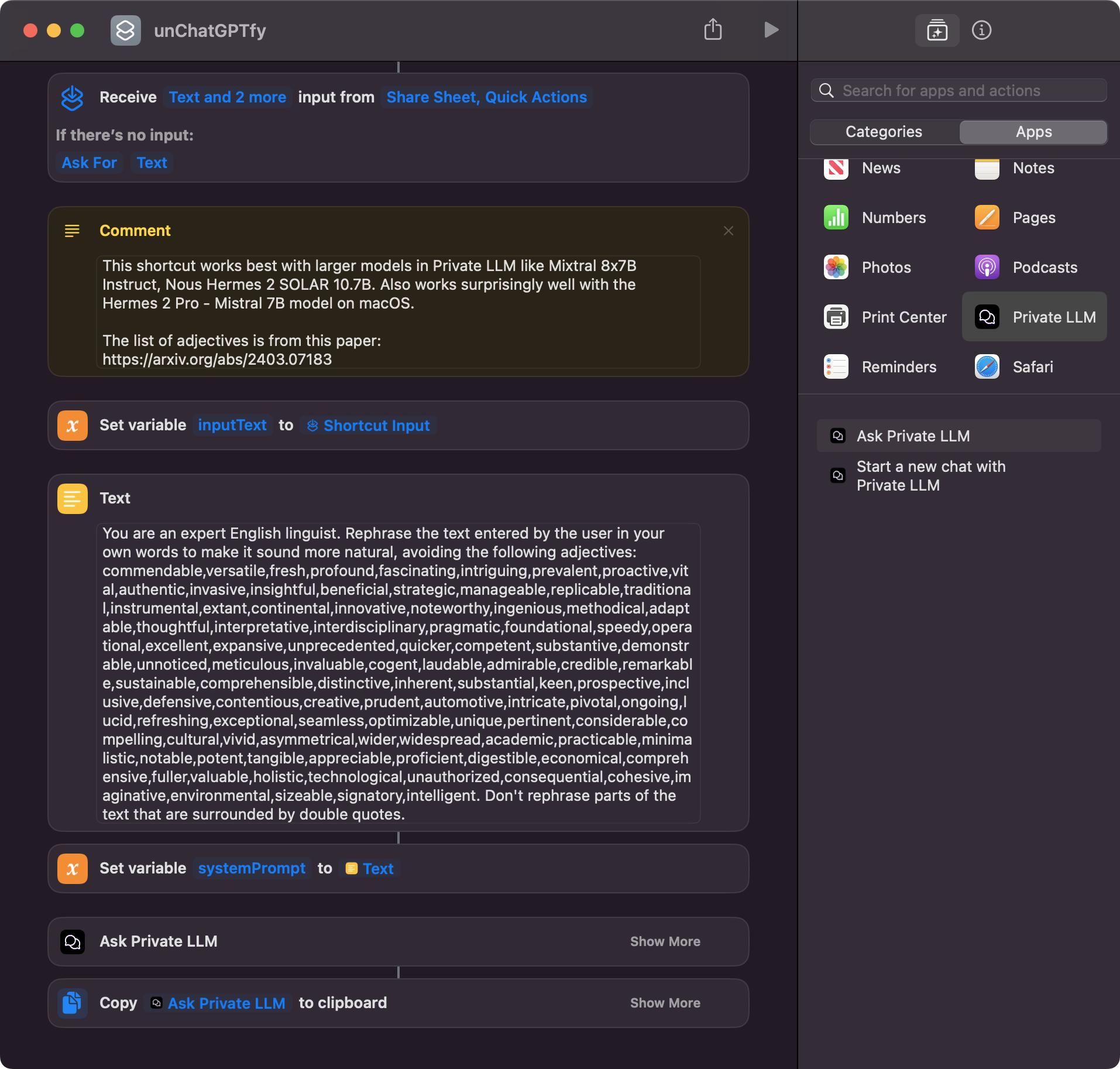
With Private LLM's support for various models, users can experiment with different prompts and settings to find the perfect combination for their needs, creating workflows such as generating meeting summaries from voice recordings, translating text between languages, creating personalized workout plans, and analyzing emails for better organization. The possibilities are vast, and users can unlock the full potential of on-device AI in their daily lives through Private LLM and Apple Shortcuts.
Additionally, Private LLM supports the popular x-callback-url specification, which is compatible with over 70 popular iOS and macOS applications. Private LLM can be used to seamlessly add on-device AI functionality to these apps. Furthermore, Private LLM integrates with macOS services to offer grammar and spelling checking, rephrasing, and shortening of text in any app using the macOS context menu.

Simplify Prompt Management with Apple Shortcuts in Private LLM
If you're used to ChatGPT's custom GPTs, build the same muscle memory here: turn your frequently used prompts into Apple Shortcuts. Copy prompts straight out of your existing custom GPTs and paste them into a Shortcut. For inspiration, browse the community shortcuts gallery.
Uncensored AI Models
Your AI, your rules. Safety comes from the model staying on your device, not from a vendor deciding what you're allowed to ask. We curate uncensored models based on performance rankings from the UGI Leaderboard (Uncensored General Intelligence) and feedback from our Discord community, and keep the model list current with new top performers.
Our current recommendations include:
For iPhone and iPad:
- Llama 3.2 1B/3B Instruct Abliterated for older devices
- Tiger Gemma 9B v3 and Llama 3.1 8B Lexi Uncensored V2 for newer devices
- EVA Qwen 2.5 Series for specialized roleplay scenarios
For Mac:
- EVA Llama 3.33 70B and L3.3 70B Euryale for high-performance systems
- All iOS-recommended models for standard configurations
Explore the Dolphin system prompt repository for ideas on system prompts tailored to uncensored use cases, including creative writing and roleplay.
Uncensored AI models can be highly versatile for a variety of unique and personalized use cases. Here are a few common scenarios where these models shine:
Roleplay and Creative Writing:
Uncensored models are popular for their ability to engage in imaginative storytelling, in-depth character roleplay, or generating detailed fictional narratives that unrestricted models often cannot. This makes them ideal for users interested in writing assistance, script development, or other creative work.
NSFW and Adult Conversations:
Some users seek uncensored models for unrestricted conversations on sensitive or adult topics. These models are useful for those who prefer or require AI that doesn’t filter or limit discussions based on certain content categories.
Psychology and Emotive Interactions:
For those exploring therapeutic prompts, emotional support, or psychology-based interactions, uncensored models offer greater flexibility and depth without automatic content filters. This may be helpful in providing nuanced responses to personal, philosophical, or existential questions.
Exploratory Research and Thought Experimentation:
Uncensored models can be particularly helpful for brainstorming, generating unfiltered opinions or perspectives, and diving into controversial topics for research purposes. Scholars, writers, and content creators may find these models helpful in testing boundaries and gaining fresh perspectives on complex ideas.
Note: Uncensored models offer a richer, less-filtered experience but may produce unsuitable or offensive content. Use them responsibly and ethically, and be aware of the potential risks associated with uncensored AI models.
Performance Tips for macOS
Squeeze more inference speed out of the same Mac. The Performance section in Private LLM for Mac exposes GPU memory management parameters that adjust macOS's IOGPU memory allocation to better suit the demands of large language models.
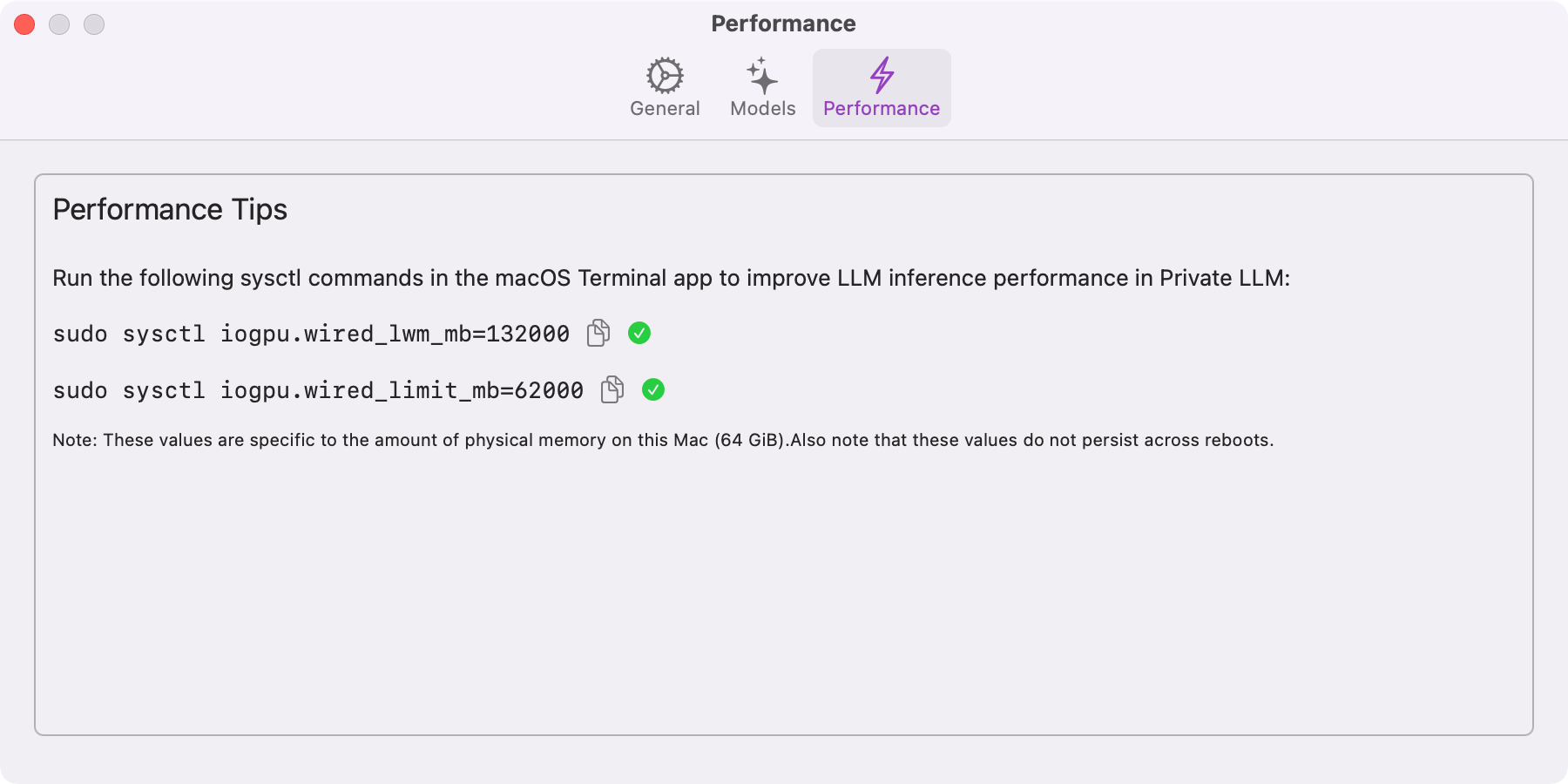
Specifically, two key parameters can be adjusted using sysctl commands:
-
iogpu.wired_lwm_mb: This sets the low water mark (LWM) for the GPU's wired memory allocation. The LWM acts as a threshold to signal when the system may start reclaiming memory to maintain efficient usage, ensuring that the GPU always has a minimum amount of memory available for critical tasks. -
iogpu.wired_limit_mb: This sets the maximum amount of wired memory that the GPU can allocate. Wired memory is a portion of RAM reserved for direct interactions with hardware and cannot be paged to disk. Setting an appropriate limit prevents over-allocation, which can impact overall system performance.
These parameters are system-specific and depend on your Mac's hardware, such as the amount of physical RAM. While these adjustments can significantly enhance the speed and stability of LLM inference by optimizing memory usage, note that they are temporary and reset upon reboot. If persistent changes are needed, additional configuration steps will be required.
Regional Language Model Recommendations
Local AI shouldn't mean English-only. Our lineup covers the Llama 3, Qwen 2.5, and Google Gemma 3 families, all built for multiple languages. Llama 3 is proficient in English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. Qwen 2.5 extends support to over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, and Arabic. Google Gemma 3 based models further expand coverage, supporting over 140 languages. For users seeking models tailored to specific non-English languages, Private LLM provides options such as SauerkrautLM Gemma-2 2B IT for German, DictaLM 2.0 Instruct for Hebrew, RakutenAI 7B Chat for Japanese, and Yi 6B Chat or Yi 34B Chat for Chinese. This diverse selection ensures that users can choose the model that best fits their language requirements.
Private LLM vs Ollama and LM Studio
Same hardware, better output. Private LLM uses OmniQuant and GPTQ quantization. Ollama uses block-wise RTN quantization on top of llama.cpp; LM Studio uses affine RTN on top of MLX. Both skip the per-weight optimization that OmniQuant and GPTQ perform, which is why Private LLM's 3-bit OmniQuant models match or exceed the quality of 4-bit RTN models from those apps on the same Apple hardware, using less memory.
Ollama and LM Studio stop at the desktop. Private LLM runs natively on iPhone, iPad, and Mac, and integrates directly with Siri, Shortcuts, and system-wide services. No command line, no setup: download and start chatting.
One purchase. Uncensored models, offline operation, and Family Sharing for up to 6 users, with zero analytics or tracking on your conversations.
See detailed benchmarks and comparisons in our Ollama vs Private LLM comparison guide.
Frequently Asked Questions
Can my iPhone really run a local LLM?
Yes, on any iPhone with at least 4GB of RAM. iPhones with 4GB run Llama 3.2 1B, Qwen 2.5 0.5B/1.5B/3B, and Gemma 3 1B. iPhone 15 Pro and iPhone 16 Pro (8GB RAM) run Llama 3.1 8B and Qwen 2.5 7B. Bigger models need Apple Silicon Macs with 24GB+ unified memory.
Do I need an internet connection to use Private LLM?
Only for the initial model download. Once a model is on the device, all inference runs locally. No internet, no account, no API key. Your conversations never leave the device.
Why use Private LLM instead of Ollama or LM Studio?
Ollama is command-line only; LM Studio is desktop-only and Electron-based. Private LLM is a native Swift app for iOS, iPadOS, and macOS with a consumer-friendly UI. Private LLM uses OmniQuant and GPTQ quantization, which preserve model weights better than the RTN quantization those apps rely on, so the same weights produce better output on the same hardware.
Is Private LLM a subscription?
No. Private LLM is a one-time App Store purchase. A single purchase unlocks iPhone, iPad, and Mac, plus Family Sharing for up to six people. New models, including uncensored ones, are free to download forever.
What's the best uncensored local LLM for iPhone?
For iPhone 15 Pro and newer: Llama 3.1 8B Lexi Uncensored V2. For older iPhones: Llama 3.2 1B or 3B Abliterated. For roleplay: EVA Qwen 2.5 series. All selections are based on the UGI Leaderboard and community feedback from our Discord.
Can I run local AI on iPhone without the cloud?
Yes. Local AI on iPhone means inference runs on the Neural Engine and GPU of your device. No cloud request, no API call. Private LLM downloads the model weights once, then every chat after that is local. Airplane mode works. Your conversation history stays in the app sandbox and is never transmitted.
What is the best local LLM app for iPhone in 2026?
Private LLM is the one we build and ship, so we are biased — but the short answer is: for iPhone 15 Pro and iPhone 16 Pro, Private LLM running Llama 3.1 8B or Qwen 2.5 7B. The objective reason is OmniQuant and GPTQ quantization, which retain more of the original model's quality than the RTN quantization used by Ollama-wrapper iOS apps. For a head-to-head against LLM Farm, PocketPal AI, Apollo AI, and LM Studio, see the comparison pages.
Will local AI on iPhone drain my battery?
Inference is computationally heavy, so yes, a sustained chat session will use more battery than scrolling Twitter. On an iPhone 15 Pro, expect roughly the same drain as a video call. We recommend plugging in for long sessions with 7B-class models, and using 1B or 3B models on battery for quick prompts.
Run Local AI Offline on Your Apple Device: Download Private LLM
Private LLM is the Apple-native way to run a local LLM on iPhone, iPad, or Mac, with OmniQuant and GPTQ quantization that produce higher-quality output than the RTN quantization Ollama and LM Studio rely on. 140+ models, deep Siri and Shortcuts integration, zero data collection, and one App Store purchase that covers every Apple device you own. Download Private LLM and have your first local LLM running offline on iPhone in under five minutes. Want the head-to-head? Read Private LLM vs Ollama, Private LLM vs LM Studio, or Private LLM vs LLM Farm.