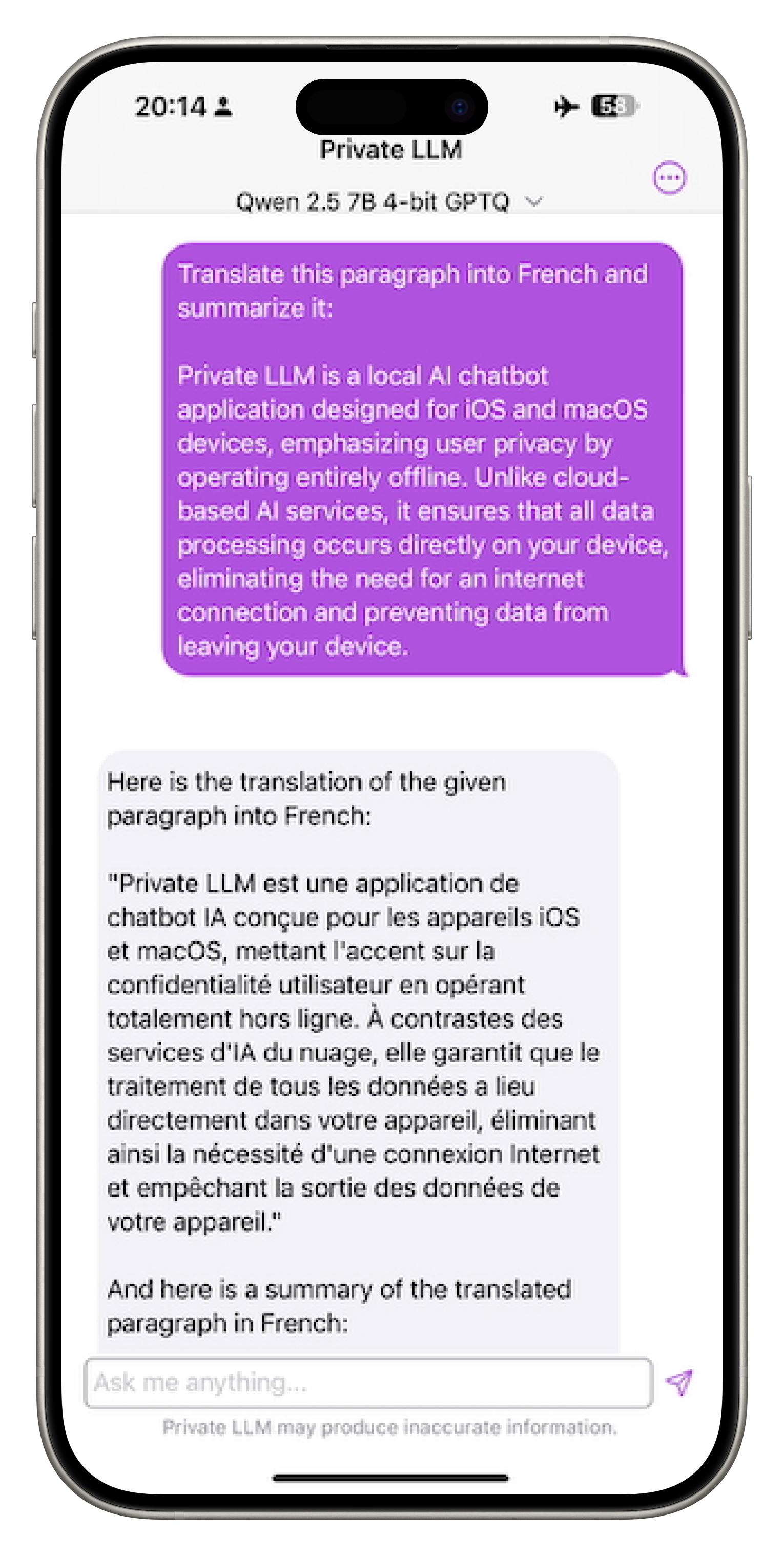
Qwen 2.5 and Qwen 2.5 Coder Models Now Available on Private LLM for iPhone, iPad, and Mac
Private LLM now supports the Qwen 2.5 and Qwen 2.5 Coder models, offering cutting-edge performance for AI tasks locally on iPhone, iPad, and Mac. This update brings models ranging from 0.5B to 32B parameters, optimized for local use and enhanced by efficient GPTQ quantization. Whether you are a developer, researcher, or an AI enthusiast, this release makes advanced language model capabilities more accessible while preserving your privacy.
How Qwen 2.5 Excels in Performance Benchmarks:
Benchmarks provide a quantifiable way to assess the capabilities of AI models across coding, reasoning, and text generation tasks. Below are detailed results for Qwen 2.5 models, showing their strengths compared to other leading models.
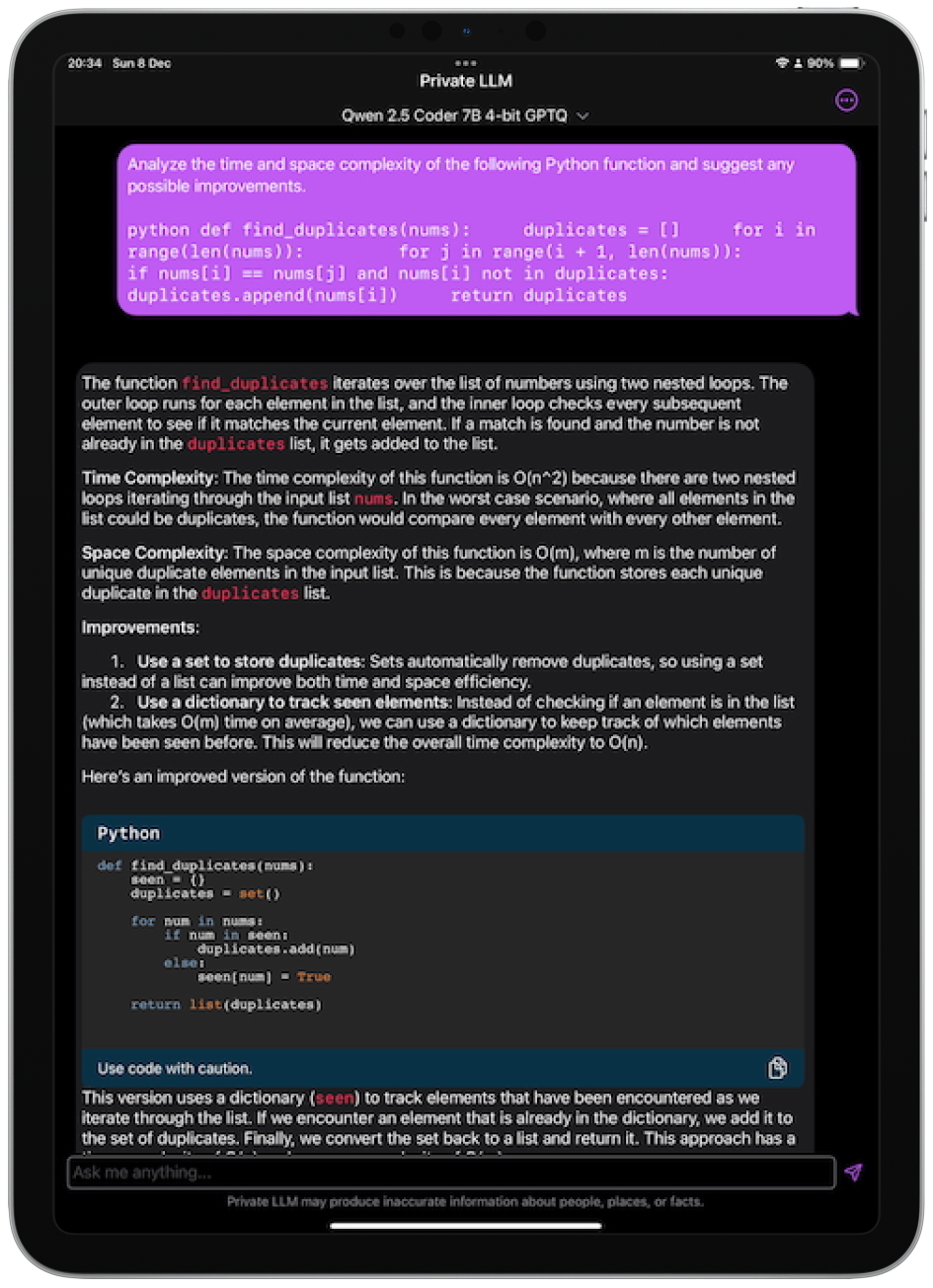
Qwen 2.5 Coder Coding Performance:
The HumanEval benchmark tests a model's ability to solve coding problems in Python. The MBPP benchmark focuses on small programming tasks. These benchmarks demonstrate Qwen 2.5 Coder's exceptional coding capabilities.
Benchmark | Qwen 2.5 Coder 32B | GPT-4o | Claude 3.5 Sonnet | DeepSeek Coder V2 | CodeStral 22B |
|---|---|---|---|---|---|
HumanEval | 92.7 | 92.1 | 92.1 | 88.4 | 78.1 |
MBPP | 90.2 | 86.8 | 91.0 | 89.2 | 73.3 |
LiveCodeBench | 31.4 | 34.6 | 31.6 | 27.9 | 22.6 |
Qwen 2.5 Coder performs comparably to GPT-4o and Claude 3.5 Sonnet in coding accuracy but offers the unique advantage of running entirely offline on iPhone, iPad, and Mac using Private LLM.

Qwen 2.5 32B Reasoning and Knowledge:
The MMLU-redux and MATH benchmarks evaluate reasoning, knowledge, and mathematical problem-solving capabilities.
Benchmark | Qwen 2.5 32B | GPT4-o Mini | Gemma2-27B | Qwen 2.5 14B |
|---|---|---|---|---|
MMLU-redux | 83.9 | 81.5 | 75.7 | 80.0 |
MATH | 83.1 | 70.2 | 54.4 | 80.0 |
GSM8K | 95.9 | 93.2 | 90.4 | 94.8 |
Takeaway: Qwen 2.5 32B excels in tasks requiring general knowledge and problem-solving, surpassing many competitors.
Device Compatibility and RAM Requirements
Running advanced models like Qwen 2.5 locally requires sufficient RAM to handle the computational workload. Below are the detailed requirements for macOS and iOS devices.
macOS RAM Requirements
Model Name | Minimum RAM | Context Length |
|---|---|---|
Qwen 2.5 0.5B Unquantized | Any Apple Silicon Mac | 32k |
Qwen 2.5 7B GPTQ | 16GB or more | 8k (32k on 16GB or higher) |
Qwen 2.5 Coder 14B GPTQ | 16GB or more | 8k (32k on 24GB or higher) |
Qwen 2.5 Coder 32B GPTQ | 24GB or more | 8k (32k on 48GB or higher) |
iOS RAM Requirements
Model Name | Minimum RAM | Device Type |
|---|---|---|
Qwen 2.5 1.5B GPTQ | 4GB | Most iOS devices |
Qwen 2.5 7B GPTQ | 8GB | iPhone Pro models |
Qwen 2.5 Coder 14B GPTQ | 16GB | High-end (1TB+) Apple Silicon iPads |
Private LLM vs. Other Local Apps like Ollama: What Sets It Apart
Private LLM outperforms other local LLM inference apps like Ollama, LM Studio, or any other Llama.cpp/MLX wrapper in two critical areas:
1. Faster Inference Performance:
Models optimized with GPTQ quantization in Private LLM run faster, providing quicker responses even for complex tasks, compared to RTN-quantized models used by other apps.
2. Improved Model Perplexity:
GPTQ quantization maintains high model fidelity, enabling Qwen 2.5 models to produce more coherent and contextually accurate responses than alternatives like those found on Ollama and LM Studio.
With the integration of Qwen 2.5 and Qwen 2.5 Coder models, Private LLM continues to lead in delivering advanced AI capabilities locally. These models offer exceptional performance across coding, reasoning, and multilingual tasks, all while running entirely offline. Whether you’re using an iPhone, iPad, or Mac, you can enjoy unparalleled privacy and performance.
Ready to experience the difference? Download Private LLM and start exploring Qwen 2.5 today.