Private LLM (formerly Personal GPT) Secure, Private AI Chatbot That Works Locally on Your iPhone, iPad and Mac

No Internet? No Problem! Private LLM Works Anywhere, Anytime!

Harness the Power of Open-Source AI with Private LLM
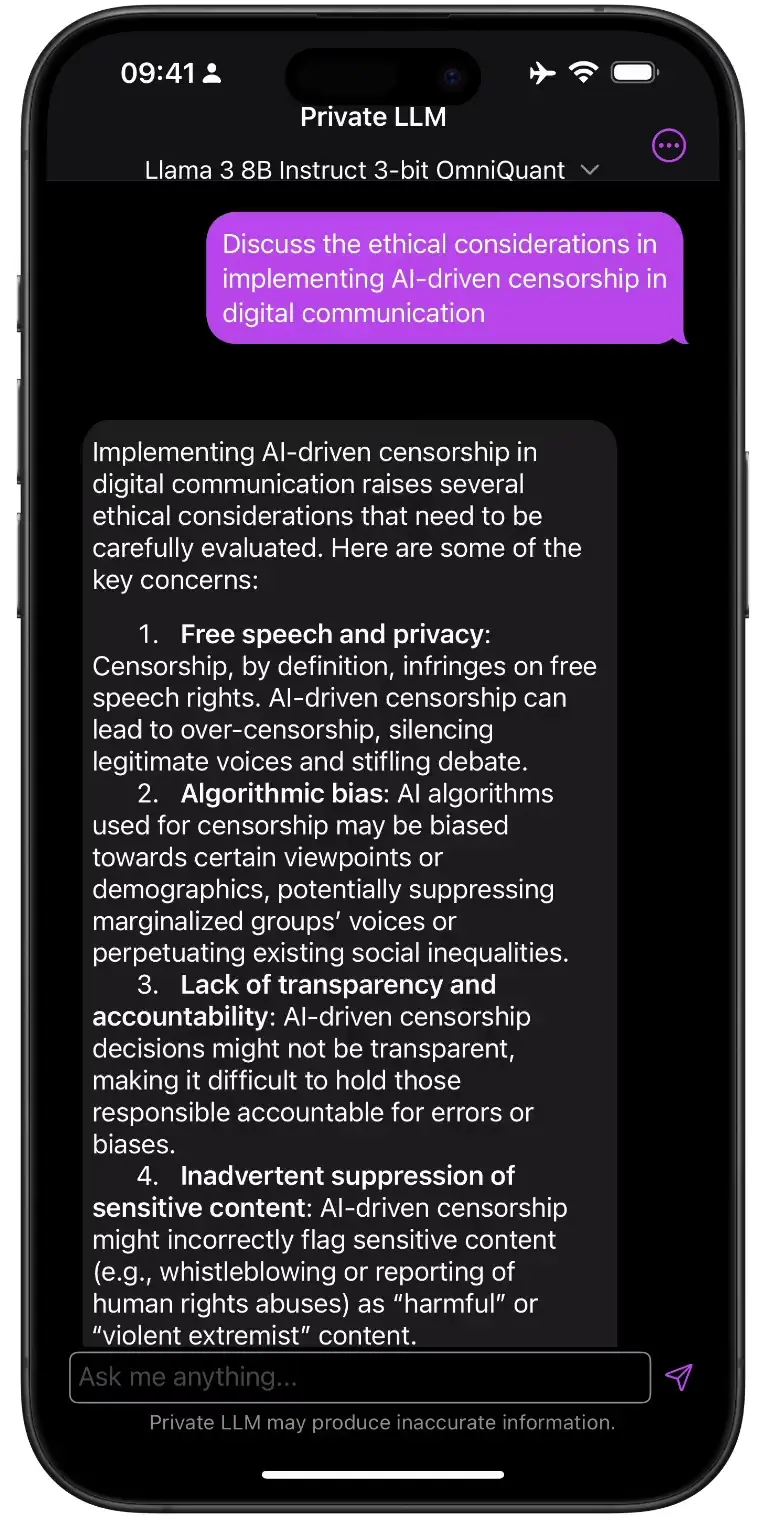
Craft Your Own AI Solutions: No Code Needed with Siri and Apple Shortcuts
Universal Access with No Subscriptions
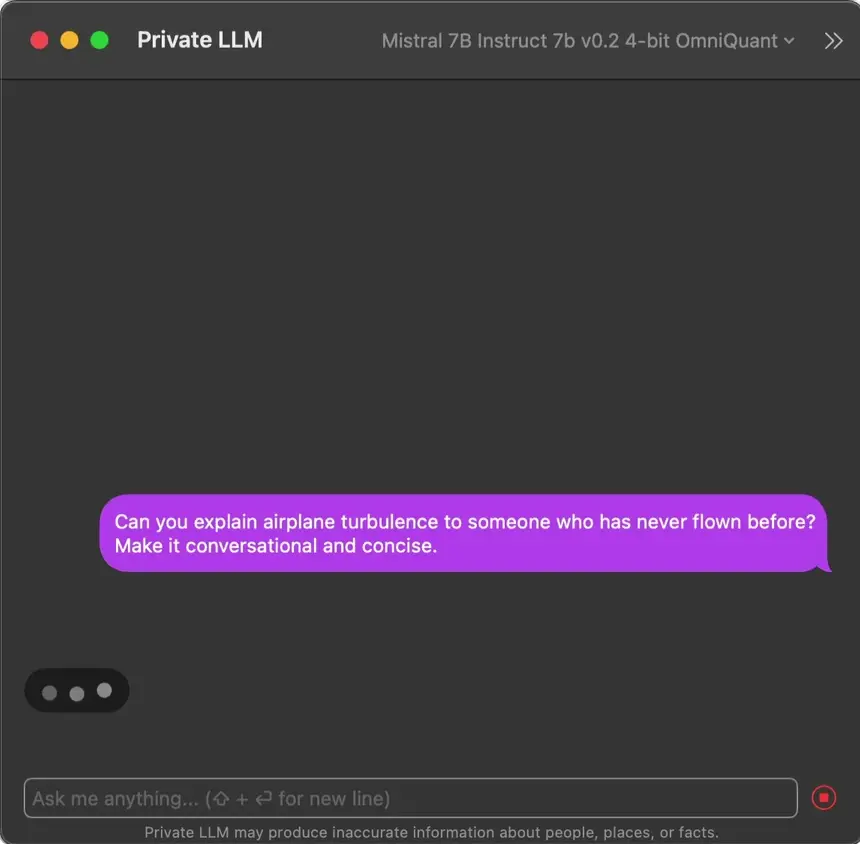
AI Language Services Anywhere in macOS

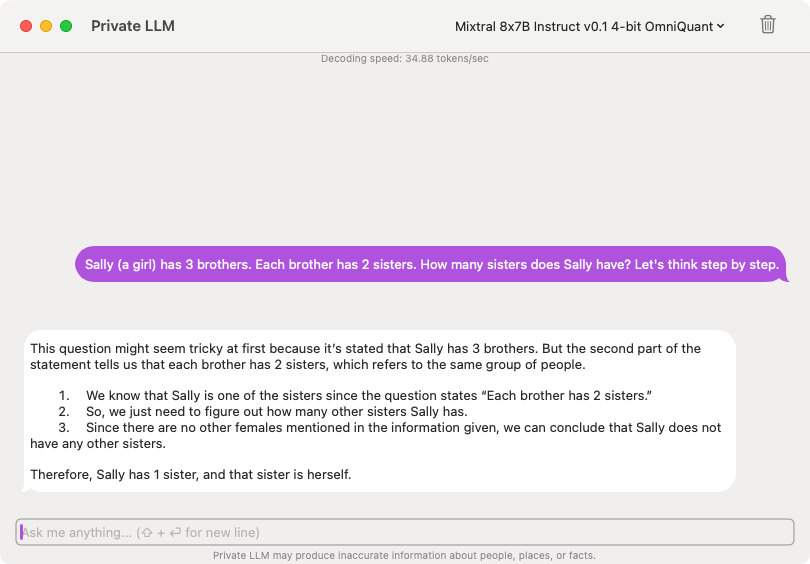
Superior Model Performance With State-Of-The-Art Quantization
See what our users say about us on the App Store
Possibly the single best app purchase I've ever made. The developer is constantly improving it and talking with users on Discord and elsewhere. One price includes Mac, iPhone, and iPad versions (with family sharing). Mac shortcuts can be used to create what amount to custom GPTs. (There's even a user-contributed, quite clever bedtime story generator on the website.) The 10.7B-parameter SOLAR LLM (one of many included) running on my 16 GB M1 MacBook Air gives me fast responses that are subjectively almost on the level of GPT-3.5. For something running completely locally with full privacy, it's remarkable. More RAM allows an even larger choice of language models. But the tiniest model running on my iPhone 12 Pro is usable. (Tip: Experiment with changing the system prompt to fine-tune it for your purposes.)
Download the Best Open Source LLMs
Mixtral 8x7B Based Models
Apple Silicon Macs with at least 32GB of RAMLlama 33B Based Models
Apple Silicon Macs with at least 24GB of RAMLlama 2 13B Based Models
Apple Silicon Macs with at least 16GB of RAMCodeLlama 13B Based Models
Apple Silicon Macs with at least 16GB of RAMLlama 2 7B Based Models
All Intel and Apple Silicon MacsSolar 10.7B Based Models
Apple Silicon Macs with at least 16GB of RAMPhi-2 3B Based Models
All Intel and Apple Silicon MacsMistral 7B Based Models
All Intel and Apple Silicon MacsStableLM 3B Based Models
All Intel and Apple Silicon MacsYi 6B Based Models
All Intel and Apple Silicon MacsYi 34B Based Models
Apple Silicon Macs with at least 24GB of RAMPhi-3 Mini 3.8B Based Models
on devices with 6GB or more RAMLlama 3 8B Based Models
on devices with 6GB or more RAMMistral 7B Based Models
on devices with 6GB or more RAMPhi-2 3B Based Models
on devices with 4GB or more RAMH2O Danube Based Models
on all devicesStableLM 3B Based Models
on devices with 4GB or more RAMYi 6B Based Models
on devices with 6GB or more RAMExplore shortcuts created by users who've transformed their daily routines using Private LLM. Feeling inspired? Share your own shortcut masterpiece with us through the contact form.
Private LLM is your private AI chatbot, designed for privacy, convenience, and creativity. It operates entirely offline on your iPhone, iPad, and Mac, ensuring your data stays secure and confidential. Private LLM is a one-time purchase on the App Store, allowing you unlimited access without any subscription fees. nb: We hate subscriptions, and we aren’t hypocrites to subject our users to what we hate.
Private LLM works offline and uses a decoder only transformer (aka GPT) model that you can casually converse with. It can also help you with summarising paragraphs of text, generating creative ideas, and provide information on a wide range of topics.
Absolutely not. Private LLM is dedicated to ensuring your privacy, operating solely offline without any internet access for its functions or accessing real-time data. An internet connections is only required when you opt to download updates or new models, during which no personal data is collected or transmitted, exchanged or collected. Our privacy philosophy aligns with Apple's stringent privacy and security guidelines, and our app upholds the highest standards of data protection. It's worth noting that, on occasion, users might inquire if Private LLM can access the internet, leading to potential model hallucinations suggesting it can. However, these responses should not be taken as factual. If users would like to independently verify Private LLM’s privacy guarantees, we recommend using network monitoring tools like Little Snitch. This way, you can see for yourself that our app maintains strict privacy controls. For those interested in accessing real-time information, Private LLM integrates seamlessly with Apple Shortcuts, allowing you to pull data from RSS feeds, web pages, and even apps like Calendar, Reminders, Notes and more. This feature offers a creative workaround for incorporating current data into your interactions with Private LLM, while still maintaining its offline privacy-first ethos. If you have any questions or need further clarification, please don't hesitate to reach out to us.
Firstly, Private LLM stands out from other local AI solutions through its advanced model quantization technique known as OmniQuant. Unlike the naive Round-To-Nearest (RTN) quantization used by other competing apps, OmniQuant quantization is an optimization based method that uses learnable weight clipping. This method allows for a more precise control over the quantization range, effectively maintaining the integrity of the original weight distribution. As a result, Private LLM achieves superior model performance and accuracy, nearly matching the performance of an un-quantized 16 bit floating point (fp16) model, but with significantly reduced computational requirements at inference time.
While the process of quantizing models with OmniQuant is computationally intensive, it's a worthwhile investment. This advanced approach ensures that the perplexity (a measure of model's text generation quality) of the quantized model remains much closer to that of the original fp16 model than is possible with the naive RTN quantization. This ensures that Private LLM users enjoy a seamless, efficient, and high-quality AI experience, setting us apart other similar applications.
Secondly, unlike almost every other competing offline LLM app, Private LLM isn’t based on llama.cpp. This means advanced features that aren’t available in llama.cpp (and by extension apps that use it) like attention sinks and sliding window attention in Mistral models are available in Private LLM, but unavailable elsewhere. This also means that our app is significantly faster than competition on the same hardware (YouTube videos comparing performance).
Finally, we are machine learning engineers and carefully tune quantization and parameters in each model to maximize the text generation quality. For instance, we do not quantize the embeddings and gate layers in Mixtral models because quantizing them badly affects the model’s perplexity (needless to mention, our competition naively quantize everything). Similarly with the Gemma models, quantizing the weight tied embeddings hurts the model’s perplexity, so we don’t (while our competitors do).
By prioritizing accuracy and computational efficiency without compromising on privacy and offline functionality, Private LLM provides a unique solution for iOS and macOS users seeking a powerful, private, and personalized AI experience.
After a one-time purchase, you can download and use Private LLM on all your Apple devices. The app supports Family Sharing, allowing you to share it with your family members.
Unlike almost all other AI chatbot apps that are currently available, Private LLM operates completely offline and does not use an external 3rd party API, ensuring your data privacy. There's no tracking or data sharing. Your data stays on your device. Plus, it's a one-time purchase, giving you lifetime access without having to worry about recurring subscription fees.
Private LLM can analyse and summarise lengthy paragraphs of text in seconds. Just paste in the content, and the AI will generate a concise summary, all offline. You could also use Private LLM for rephrasing and paraphrasing with prompts like:
- Give me a TLDR on this: [paste content here]
- You’re an expert copywriter. Please rephrase the following in your own words: [paste content]
- Paraphrase the following text so that it sounds more original: [paste content]
Absolutely! Private LLM can generate insightful suggestions and ideas, making it a powerful tool for brainstorming and problem-solving tasks. Here are some example brainstorming prompts that you can try asking Private LLM. Please feel free to experiment and try out your own prompts.
- Can you give me some potential themes for a science fiction novel?
- I’m planning to open a vegan fast-food restaurant. What are the weaknesses of this idea?
- I run a two year old software development startup with one product that has PMF, planning on introducing a new software product in a very different market. Use the six hats method to analyse this.
- Utilise the Golden Circle Model to create a powerful brand for a management consulting business.
Sampling temperature and Top-P are universal inference parameters for all autoregressive causal decoder only transformer (aka GPT) models, and are not specific to Private LLM. The app has them set to reasonable defaults (0.7 for Sampling temperature and 0.95 for Top-p), But you can always tweak them and see what happens. Please bear in mind that changes to these parameters do not take effect until the app is restarted.
These parameters control the tradeoff between deterministic text generation and creativity. Low values lead to boring but coherent response, higher values lead to creative but sometimes incoherent responses.
Yes. Private LLM has two app intents that you can use with Siri and the Shortcuts app. Please look for Private LLM in the Shortcuts app. Additionally, Private LLM also supports the x-callback-url specification which is also supported by Shortcuts and many other apps. Here’s an example shortcut using the x-callback-url functionality in Private LLM.
Private LLM is performing on-device inference on a large language model, which is a memory-intensive process. The iOS operating system sends the app a memory warning; and not acting on the warning will lead to iOS terminating the app. In the interest of stability, the app immediately stops generating text. If you're running several apps simultaneously or your device has limited memory, you might receive a memory warning. Closing unused apps in the background and/or restarting the app device can often resolve this.
This could be due to the device running low on memory, or if the task given to Private LLM is particularly complex. In such cases, consider closing memory hungry apps that might be running in the background and try breaking down the request into smaller, more manageable tasks for the LLM to process. In the latter case, simply responding with “Continue”, “Go on” or “Tell me” also works.
We’re sorry to hear you’re considering a refund. You can request a refund through the Apple App Store. Simply navigate to your Apple account's purchase history, find Private LLM, and click on 'Report a Problem' to initiate the refund process. We would also love to hear from you about how we can improve. Please reach out to us with your feedback.
Whether you've got a question or you're facing an issue with Private LLM, we're here to help you out. Just drop your details in the form below, and we'll get back to you as soon as we can.